Scikit-Learn ML Foundations - Classification & Regression Coursework
A five-part scikit-learn coursework series building hands-on fluency in classification and regression - from loading toy datasets through train/test splits to evaluating models with confusion matrices and prediction plots.
Business Problem
Coursework framing rather than a market problem. The Advanced Python module needed to move from language fundamentals into applied machine learning, building the muscle memory to load a dataset, split it, fit a model, predict, and evaluate the results - the same loop that underlies almost every real ML project before any deep learning or production tooling enters the picture.
Tools Used
Key Features
- Iris classification: KNN on the classic 150-sample three-species dataset, with a Seaborn confusion matrix to visualize misclassifications
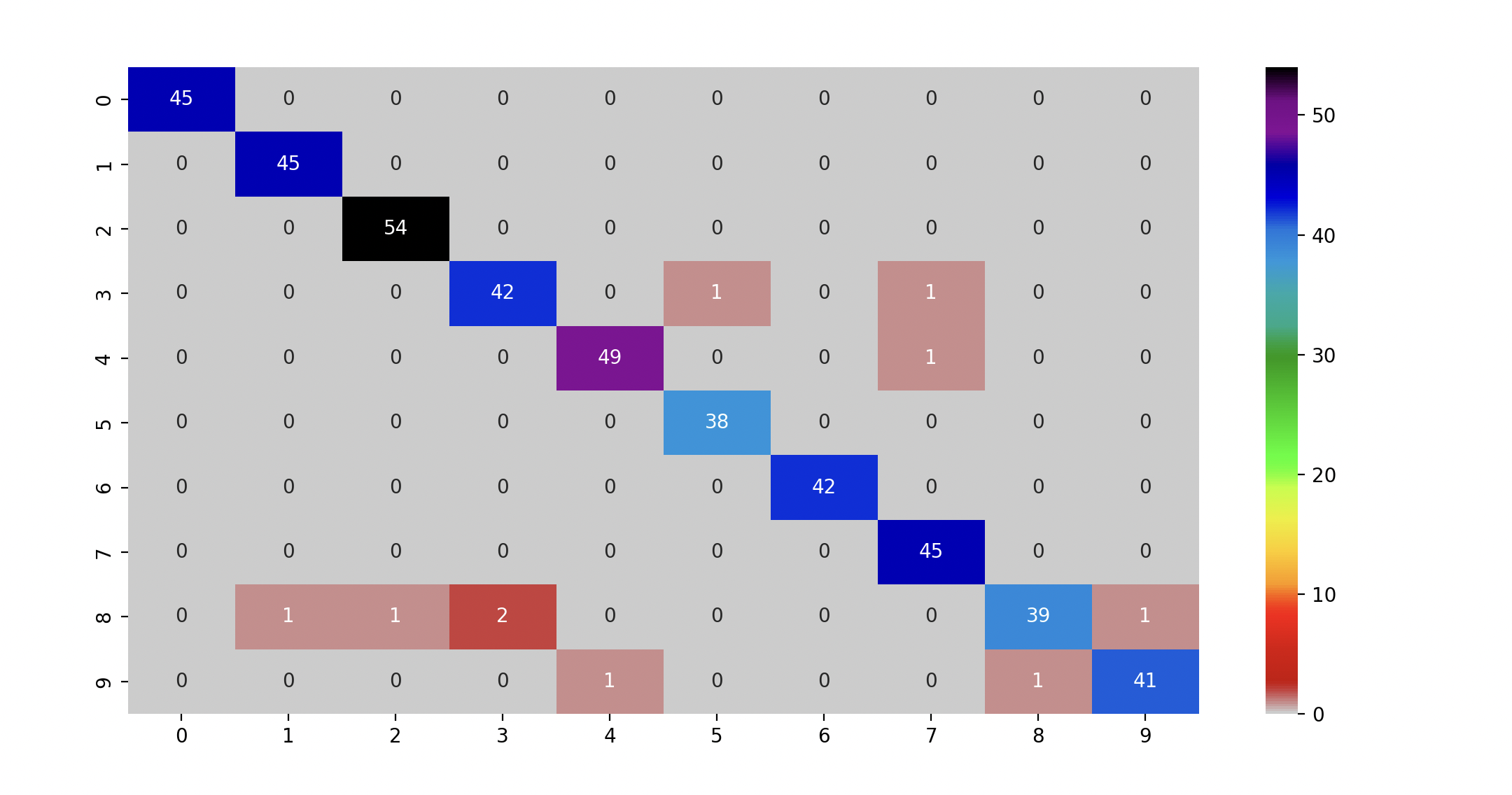
- Handwritten Digits classification: KNN on 8x8 pixel digit images, plotting sample inputs and reporting accuracy plus a 10x10 confusion matrix
- Diabetes regression: Linear Regression on the scikit-learn diabetes dataset, printing coefficients and intercept and plotting predicted vs. expected with a y=x reference line
- Auto MPG regression: Linear Regression on the Hugging Face auto-mpg dataset, with cleaning of non-numeric columns, scatter of weight vs. mpg, and an actual-vs-predicted plot
- California Housing regression: Linear Regression across all eight features, per-feature scatterplots vs. median house value, and an expected-vs-predicted plot bounded to a shared axis range
- Consistent workflow across all five: load, inspect shape and DESCR, train_test_split with a fixed random_state, fit, predict, and visualize - so the pattern stays visible across problem types
My Role & Contribution
Sole student author. Wrote each script end-to-end, picked the visualization that best exposed model behavior for each dataset (confusion matrix for classification, prediction-vs-actual scatter for regression), and kept the train/test/evaluate loop structurally identical across the five so the underlying scikit-learn pattern is easy to read at a glance.
Biggest Challenge
The Auto MPG dataset shipped with non-numeric values (notably '?' in the horsepower column) that broke LinearRegression.fit silently with confusing dtype errors. Solved by dropping the non-numeric car-name column, coercing everything else with pd.to_numeric(errors='coerce'), and dropping rows with NaNs before splitting - a small but real lesson in why data cleaning is the unglamorous majority of any ML project.
What I Learned
The scikit-learn API is deliberately uniform: load, split, fit, predict, score - the same five steps regardless of whether the model is KNN, Linear Regression, or anything else in the library. That uniformity is the whole point. Once the loop is muscle memory, swapping algorithms or datasets becomes cheap, and attention shifts to the parts that actually matter: feature quality, data cleaning, and choosing the evaluation that exposes how the model is wrong. These foundations underpin the more applied AI work elsewhere on this portfolio.